Nathaniel Krueger
Lab 5
Regression Analysis
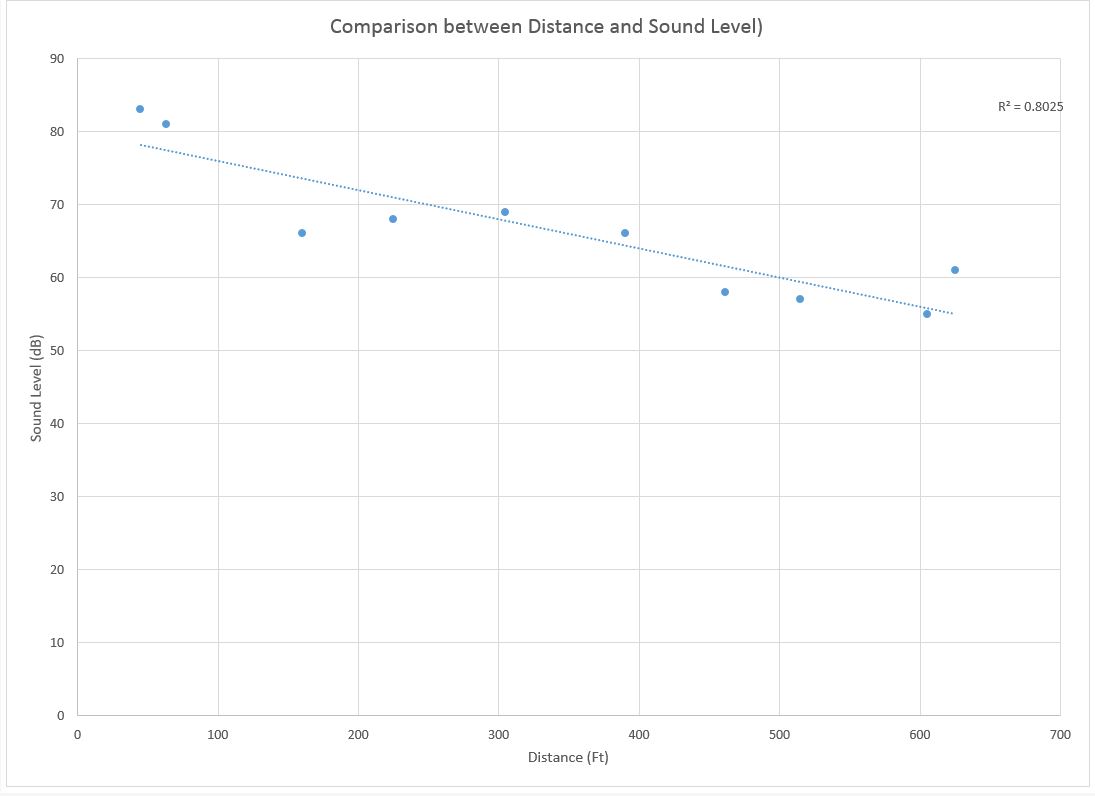
A news station is attempting to link the number of free school lunches to the crime rate. They are saying that as the number of free school lunches increases so does crime. Town X had a study done that collected the percent of kids that get free lunch and the crime rate per 100,000 people in the given area. After running a linear regression in SPSS, it has been determined that the news is not correct. There is an R-value of .416 which would leave one to think that there is not a strong correlation. A new area of town had 23.5% of kids getting free lunch and using the linear regression equation above there would be a corresponding crime rate of 22.21. After the calculations and seeing a crime rate of 22.21 with 23.5% of kids receiving free lunch, one would be not very confident in these results. The equation used to calculate the crime rate was y=a+bx (y=21.819+1.685(.235). It is a weak positive relationship between crime rates and percent of kids getting school lunches. There is a spurious relationship between the two, meaning that the news station thought that there would be a connection but it turns out there is not. The data that is discussed above is found in the tables below.


Part 2
The
UW system has asked to have enrollment analyzed in comparison to other schools,
the committee wants to know why students chose the schools that they did. The
data that could be used for this is really almost endless, so a few variables
were selected and investigated in this portion of the lab. There is no way to truly
decipher why a student chose the school that they did, but certain variables
may help us to uncover clues as to why they made the choice they did. The schools
that were investigated in this lab are UW Eau Claire and UW Green Bay. A series
of regression analysis were done in SPSS to determine if there is a link
between the variable and why they go to school where they do.
The
following operations that are done below required a fair amount of set up to
manipulate the data in a way that was used friendly. The enrollment data from
all the UW schools in all 72 counties was found under the Q drive. Along with
enrollment data there is data from a view different categories in order to
broaden our findings. An education variable was given which was the percent of people
with a bachelor’s degree for each county. An income variable was given and it
was the median household income per county. The final important data that was
examined was the distance each school is from the center of the county and the
number of students attending the different UW schools. The variables that were
determined to help find out why students selected the schools they did were median
household income and percent of people with bachelor’s degrees. It is
reasonable to infer that counties that have more people with bachelor’s degrees
would have more people that decide to also go to college. The second data set
that was used is the median household income, it is common belief that the
higher education one has the more money they will make, and this will help
decipher that.
From
the share drive on the Q drive in the lab 5 folder, the Microsoft Excel data
called UW system was opened. In a new excel file only the data that was needed
was transferred over in order to make it easier to work with. UW Eau Claire and
UW Green Bay enrollments, Median household income, population and percent of
people with bachelor’s degrees. The first step to making this lab work was to
normalize the variable of county population with the distance from the
Universities. To do this the county population was divided by the distance from
the university, this was done for UW Eau Claire and UW Green Bay. This led into
SPSS as one is now able to begin running regression analyses. Once in SPSS
under the analyze tab there is a regression slide tab, and then under
regression, the linear button was selected. The students attending the
university being investigated is always used as the dependent variable. Three separate
regression equations were ran for both schools. The independent variables used
in the regression analyses is the Population/ Distance, Percent with a bachelor’s
degree, and Median household income.
For
the purposes of what is being investigated only variables that had statistical significance
were mapped in ArcMap. They were deemed statistically significant because the
null hypothesis was rejected, meaning that there was a difference between what
was being compared. After the regression analyses were completed it was found
that four of the six regressions done were deemed statistically significant. To
map these in Arc Map, the regression was ran again but this time the residuals
were saved for each county. This allowed one the ability to use the data in
ArcMap. After joining the excel data to ArcGIS, the tables were joined by GeoID
because the county names varied a little bit and caused some problems in the
join just due to uppercase letters.
Results
Below
are the tables which display the regression analysis that were run for each
variable in SPSS and four maps which display the variables that had statistical significance. Below the maps are the two regression analysis that were deemed not statistically significant.
 |
| Map 1: Eau Claire Percent of People with Bachelors Degree |
Map 1 above displays the percent of people in each county that have bachelors degrees in relationship to Eau Claire county. The darker colors are over the standard deviation, so the darker the darker the shade of color the more above the average it is. What this does is help to illustrate where a good number students attending Eau Claire are coming from. For example, Dane county which is the state capital is well over the standard deviation and this could be attributed to the fact that the Madison area tends to have a higher median income than surrounding areas.
 |
| Table 1: Eau Claire Percent of People with Bachelors Degree |
Table 1 above relates to Map 1 above, this helps to give some basis to what the map is displaying. The constant B is -126.472, that is why on the map Eau Claire county is less than the average. A few possible explanations for this is possibly that a good percentage of the work force in Eau Claire and the surrounding areas commute from out of county. The significance level of .003 leads us to reject the null hypothesis, stating that there is in fact a difference in the percentage of bachelors degree per county when compared to Eau Claire county.
 |
| Map 2: Eau Claire Population/ Distance |
Map 2 above displays the Eau Claire population divided by the distance the from the center of the county, this in turn gives us a relative idea of how close to the center of the county the university is. This map is extremely similar to Map 1, in fact at first glance the only variation is in the southeast corner of the state.
 |
| Table 2: Eau Claire Population/ Distance |
An R square value of .945 coupled with a significance level of .03, one can see why this variable is significant. There is a positive constant value of 8.518. That means that there is a positive relationship between the population/ distance when comparing Eau Claire University compared to the center location of other universities.
 |
| Map 3: Green Bay Population/ Distance |
Map 3 above illustrates the Green Bay Population divided by the Distance which then gives the relative center of the university in relationship to the rest of the counties in the state. In the map above the dark red color is well above the average and the dark orange is just slightly over the mean, then the light orange is under and mean and the yellow is even further under the average. So what can be taken from this map is that Green Bay is more towards the center of the county in comparison the other counties in Wisconsin.
 |
| Table 3: Green Bay Population/ Distance |
Table 3 above goes with the map direct above it, an R square value of .961 shows that there is a strong relationship between Green Bays Population/Distance, which in turn means that the university is more in the center of the county by population compared to other counties. This is most likely because Green Bay is the biggest city in Brown county and the university is located within the city.
 |
| Map 4: Green Bay Median Household Income |
Map 4 shows many similarities with Map 3 at first glance. The homes with a median household income appear to be sending there kids to Green Bay, as it is a dark red color which shows us that Brown county is over the average for median household income.
 |
| Table 4: Green Bay Median Household Income |
Table 4 is the table that displays the Median Household income for Green Bay. The significance value of .044 is very close to the cutoff that is used when evaluating variables at a 95% confidence ratio.
 |
| Table 5: Eau Claire Median Household Income |
Table 5 above shows the median household income for Eau Claire, at a 95% confidence interval a significance level of .104 was deemed not statistically significant.
 |
| Table 6: Green Bay Percent of People with a Bachelors Degree |
Table 6 above is the Percent of people in brown county with a bachelors degree, linked with the university. A significance level of .085 at 95% confidence was deemed not statistically significant.
Conclusion
After examining multiple variables for two different UW schools, one would come to the conclusion that they were very similar in regards to the fact that each school yielded very similar maps in there own regards. The Eau Claire maps were all similar just as the Green Bay ones were, but they both were drastically different when comparing the two schools. The regression output suggested that there was in fact a link between where students picked to go to school and the variables. Though there could potentially be 1000's of other reasons why they chose to go to school where they did. So they was a good exercise to think critically about all that goes into selecting a college and it helped to work on getting the software down with SPSS and ArcGIS. An extended study could be done with many more variables to find a true link and discuss a more concrete reasoning as to why students chose the school they did. I think that ultimately distance and population are large influences into the appeal of a certain school, also household median income is important because it can more a less tell you which counties on average have enough money to send there kids to school.